Having relied on PostgreSQL within a Patroni cluster to power our production Airflow environment for some time, I’ve recently begun exploring the database more deeply. I am consistently impressed by its robust feature set and its widespread reputation across the industry as a truly reliable, enterprise-grade database solution. This fascination inspired me to pull back the curtain and understand exactly “what is under the hood” and how PostgreSQL actually works. This blog post is the result of that journey, focusing on the essential fundamentals of PostgreSQL architecture and operation.
Introduction
Postgres is a relational database management system (RDBMS). It stores structural data & allows manipulation using SQL. Apart from being a data store it is a transactional, concurrent, extensible data engine built to adhere to ACID properties at scale.
- Atomicity - All or nothing
- Consistency - A transaction must bring the database from one valid state to another.
- Isolation - Concurrent transactions are isolated from each other.
- Durability - Data is persistent even in case of system failure.
Unlike standard relational databases, Postgres allows for custom data types, inheritance, and complex structures like JSONB and geometric objects and also allows attaching methods, operators to them.
Postgres Architecture is built around a concept of background processes and shared memory.
Background Processes
These are the essential ‘housekeeping’ processes that keep the system running. The diagram shows the Postmaster handling incoming client connections and spawning individual Backend Processes.
207 pts/0 S+ 0:00 \_ /usr/lib/postgresql/18/bin/psql -U postgres -d n8n
1 ? Ss 0:17 postgres
28 ? Ss 0:00 postgres: io worker 0
29 ? Ss 0:00 postgres: io worker 2
30 ? Ss 0:00 postgres: io worker 1
31 ? Ss 0:01 postgres: checkpointer
32 ? Ss 0:02 postgres: background writer
34 ? Ss 0:02 postgres: walwriter
35 ? Ss 0:06 postgres: autovacuum launcher
36 ? Ss 0:00 postgres: logical replication launcher
238 ? Ss 0:00 postgres: postgres postgres [local] idle
| Process | Action Performed |
|---|---|
| Postmaster | Listens for new connection requests and spawns a dedicated backend process for each client. |
| Backend Process | Executes SQL queries, manages transactions, and retrieves or modifies data for a specific connected user. |
| Background Writer | Periodically flushes “dirty” data pages from the shared buffer cache to persistent disk storage. |
| Checkpointer | Creates synchronization points by forcing all modified memory buffers to disk and updating the WAL control file. |
| WAL Writer | Continuously writes transaction log data from memory buffers to sequential Write-Ahead Log files on disk. |
| Autovacuum Launcher | Monitors table bloat and schedules worker processes to reclaim space from dead tuples. |
| Autovacuum Worker | Performs the actual cleanup of deleted/updated rows and updates table statistics for the query planner. |
| Stats Collector | Aggregates and records runtime information about table access, index usage, and row counts. |
| Archiver | Copies completed WAL segment files to a secure backup storage location for point-in-time recovery. |
| Logger | Captures system error messages and performance events and writes them to the database log files. |
Shared memory
Shared memory is the critical communication highway in PostgreSQL, allowing various background processes to access and update data without constant disk I/O.
Shared Buffer Pool Acts as the primary data cache; it loads 8KB pages from disk into memory so that multiple backend processes can read and modify the same data quickly without hitting the slow physical storage.
WAL Buffer A temporary staging area for Write-Ahead Log (WAL) records; it holds transaction logs in memory until they are flushed to disk by the WAL Writer, ensuring durability without stalling the transaction for every single write.
Commit Log (CLOG) A specialized memory area that tracks the status of every transaction (whether it is in progress, committed, or aborted), allowing processes to quickly determine if a row version (tuple) is visible based on its transaction ID.
Lock Manager Maintains a shared table of all database locks (row-level, table-level, etc.); it coordinates access between concurrent transactions to prevent them from conflicting or corrupting data during updates.
ProcArray Stores the status and metadata of all currently active backend processes; it is primarily used to generate “snapshots” for MVCC, helping the system decide which data versions are visible to which users at any given moment.
Storage
Postgres seperates logics of how querries are executed and storage i.e. how data is stored on disk.
On disk, PostgreSQL organizes data into a specific hierarchy designed for reliability and fast retrieval. Here is a breakdown of the primary storage structures:
Data Files (Heap Files) The primary storage for tables, where data is organized into 8KB pages. Rows are represented internally as “tuples,” which contain both the raw data and metadata (like transaction IDs) used for concurrency control. Instead of overwriting rows, Postgres appends new versions of rows (tuples) to these files, which is the physical foundation for MVCC.
Index Files Separate files (usually B-Trees) that store pointers to the physical locations of rows in the heap files. They allow the database to find specific data without scanning every single page in a table.
Write-Ahead Log (WAL) A sequential “journal” of every change made to the database. Before a change is applied to the main data files, it is recorded here first; this ensures that if the system crashes, the database can “replay” the log to restore its state.
TOAST Tables The Oversized Attribute Storage Technique. When a single row value (like a large JSON blob or long text) exceeds the 8KB page limit, Postgres automatically moves that specific value into a separate “TOAST” file to keep the main table lean and performant. A pointer to the TOAST file is stored in the main table.
Commit Log (CLOG) A set of files in the pg_xact directory that stores the final status of every transaction (Commited, Aborted, or In-Progress). This is the “source of truth” used to determine which row versions are visible to users.
Free Space Map (FSM) A binary file that tracks how much empty space is available in each 8KB page of a table. When a new row is inserted, Postgres consults the FSM to quickly find a page with enough room, rather than searching the whole table.
Visibility Map (VM) A simple map that tracks which pages in a table contain only “frozen” (all-visible) rows. This allows the Autovacuum process to skip those pages and helps speed up “Index-Only” scans.
MVCC & WAL are two important concepts in Postgres that enable high concurrency and data durability.
MVCC (Multi-Version Concurrency Control)
MVCC is the engine that allows multiple users to read and write to the same table simultaneously without locking each other out. The core philosophy is: “Readers never block writers, and writers never block readers.” Here is how it works at the transaction level:
The “No Overwrite” Rule
Unlike other databases that might update a row in place, Postgres never overwrites existing data.
- When you UPDATE a row, Postgres marks the old version as “obsolete” and inserts a completely new version (a new tuple) into the table.
- When you DELETE a row, it simply marks the row as “deleted” but leaves it on the disk for a while.
Transaction IDs (xmin and xmax)
Every row (tuple) on the disk has two hidden “bookkeeping” columns that manage visibility:
- xmin: The ID of the transaction that created (inserted) the row.
- xmax: The ID of the transaction that deleted or updated the row. If the row hasn’t been deleted, xmax is 0.
Snapshot Isolation
- When you start a transaction, Postgres gives you a Snapshot. This is a list of all transactions that are currently active or committed.
- The Logic: Your transaction can only “see” rows where the xmin is a transaction that was already committed before your snapshot was taken.
- The Result: If User A is updating a row but hasn’t clicked “Commit” yet, User B can still read the old version of that row. User B is essentially looking at a “version” of the database from a point in the past.
Row Visibility Flow
To determine if a row is visible to your current transaction, Postgres follows these basic rules:
- Is xmin committed? If no, the row is invisible (it’s from a future or failed transaction).
- Is xmax zero or uncommitted? If yes, the row is still valid and visible.
- Is xmax committed? If yes, the row is “dead” (deleted) and invisible to you, because a transaction finished deleting it before you looked.
The Cleanup (Vacuum)
Because every update creates a new version, the database would eventually run out of disk space. This “clutter” is called Bloat. The Autovacuum process periodically scans the table. It looks for rows where the xmax is so old that no active transaction could possibly need to see it anymore. It then clears those rows so the space can be reused for new data.
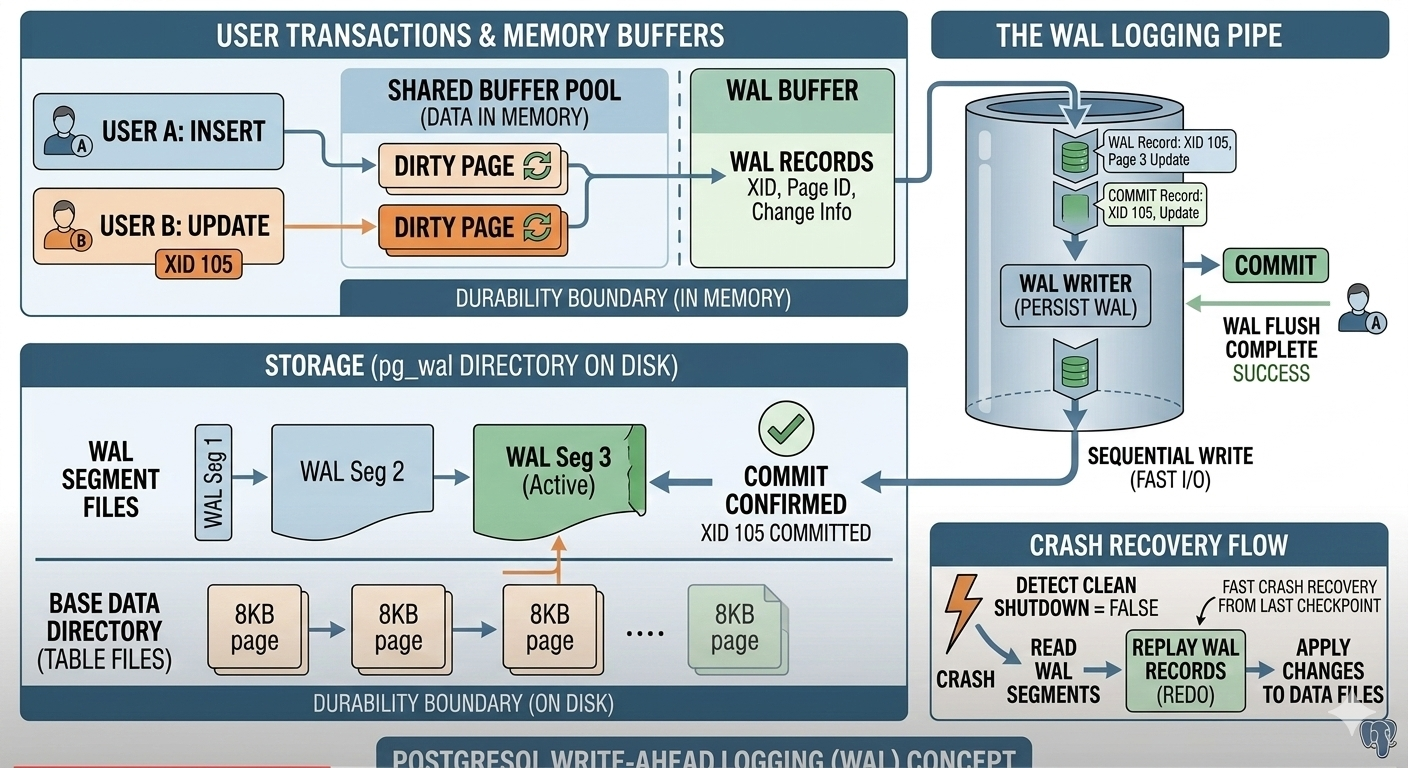
WAL (Write-Ahead Logging)
WAL is the fundamental mechanism that guarantees database durability (the ‘D’ in ACID). Its core philosophy can be summarized in one rule: “No change to data files is ever made until a description of that change has been written to the log and flushed to permanent storage.” Here is a conceptual breakdown of how WAL works:
The Problem: Memory vs. Disk Speed
To make databases fast, PostgreSQL does most of its work (reading, inserting, updating data) in memory (the Shared Buffer Pool). Writing data sequentially to a log file on disk is much faster than jumping around randomly updating massive data files. If the database crashed while changes were only in memory, those changes would be lost. WAL solves this.
The Solution: Log It First
When a transaction performs an action (e.g., UPDATE users SET age = 30 WHERE id = 1):
- PostgreSQL first modifies the data in memory (creating a “dirty page”).
- Before the change is written to the main data files, a description of the change (a “WAL record”) is constructed.
- This WAL record is written sequentially into the WAL Buffer in memory.
The WAL Writer and Durability
The key moment for durability happens during a COMMIT:
- When the application issues a COMMIT command, the transaction cannot be considered “complete” until its corresponding WAL records are safely on disk.
- The dedicated WAL Writer process is responsible for flushing WAL records from the memory buffer into sequential WAL segments on physical storage.
- Only after the WAL flush is successful does PostgreSQL report “COMMIT Complete” back to the application.
What Happens During a Crash?
- If power is lost or the OS crashes:
- Upon restart, PostgreSQL detects it didn’t shut down cleanly.
- It looks at the main data files, which might be “inconsistent” (some changes might have made it to disk, others might have been lost from memory).
- It finds the last known safe point (the last Checkpoint) in the WAL.
- It begins Replay (Redo): It reads the WAL segments sequentially from that checkpoint forward.
- It re-applies every single change described in the WAL to the main data files, bringing them to a consistent, committed state.
By using WAL, PostgreSQL achieves a balance:
- Safety: The sequential WAL write ensures durability.
- Performance: The actual data files can be updated lazily in the background by other processes (the Background Writer), allowing user transactions to finish quickly without waiting for random disk I/O.