I have been working on ceph cluster operations since past 3 years - reparing cluster osd issues, adding new osd’s, adding a new node, tweaking pg’s. During this time I came across differenet concepts of Ceph, which I am collating in this post and try to piece together all this information to get a holistic understanding of ceph.
Ceph is a open source, scalable, fault tolerant, self managing, software defined storage cluster. We have been using ceph as our storage backend on production cloud since Openstack Havana deployment. Underlay ceph is an object store, but has the ability to provide object storage, block storage and file system access to ceph clients or application. The below ceph architecture diagram will explain further how this is accomplished :
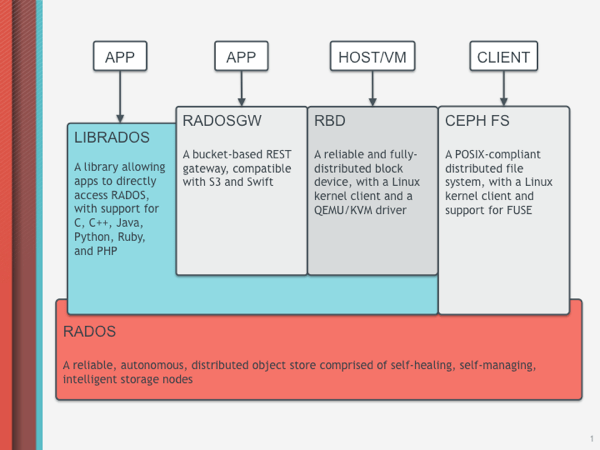
- Underlay ceph utilize - RADOS (Reliable, Autonomous, Distributed Object Store)
- An application can directly talk to ceph using LIBRADOS (RADOS Library).
- A ceph client application can access the object store using RADOSGW (RADOS Gateway).
- The host machine or a VM can utilize ceph block storage capability using RBD (RADOS Block Device).
-
File system access can be leveraged using CEPH-FS.
- CEPH OSD & CEPH MON
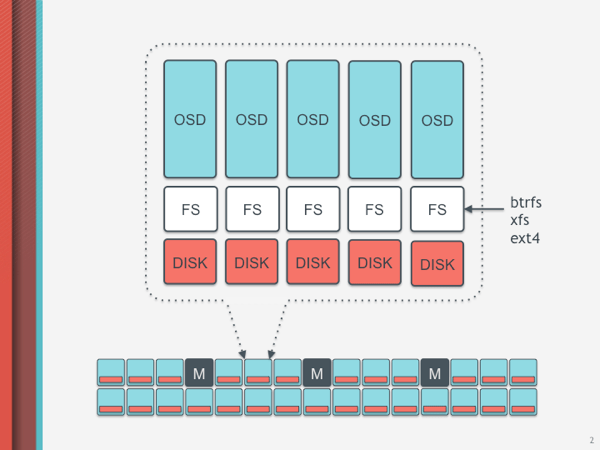
Ceph storage cluster consist of OSD (Object Storage Daemon) & ceph-mon (Ceph Monitor). Each disk on a storage node is recognized as an OSD which store the data as a object. Ceph OSD Daemons handle the read/write operations on the storage disks. Each OSD will hold several 4MB chunks, any file and block entering the cluster will be split into 4MB chunks, written in different OSDs of the cluster, and then replicated to other OSD’. Ceph maintains 3 copies of a object data to guarantee redundancy.
Ceph monitor maintains the cluster state, autherntication, logging, monitor map, manager map, OSD map, CRUSH map. These maps are used by ceph daemons to coordinate with each other. A cluster should have atleast one ceph monitor, to avoid single point of failure the ceph-mon is maintained in a quorum of 3 ceph-mon nodes. In a cluster of monitors, latency and other faults can cause one or more monitors to fall behind the current state of the cluster. For this reason, Ceph must have agreement among various monitor instances regarding the state of the cluster. Ceph always uses a majority of monitors (e.g., 1, 2:3, 3:5, 4:6, etc.) and the Paxos algorithm to establish a consensus among the monitors about the current state of the cluster.
Ceph’s OSD Daemons and Ceph Clients are cluster aware. Like Ceph clients, each Ceph OSD Daemon knows about other Ceph OSD Daemons in the cluster. This enables Ceph OSD Daemons to interact directly with other Ceph OSD Daemons and Ceph Monitors. Additionally, it enables Ceph Clients to interact directly with Ceph OSD Daemons.
- CRUSH
CRUSH map knows the topology of the cluster and is system aware. Data stored in CRUSH map is indicated using logical buckets for each host and their corresponding osd’s. Each host bucket contains an unique negative integer, weight of the bucket, alorithm used, hash algorithm, osd id and their weight.
host ceph-002 {
id -2
# weight 2.727
alg straw
hash 0 # rjenkins1
item osd.0 weight 0.909
item osd.2 weight 0.909
item osd.4 weight 0.909
}
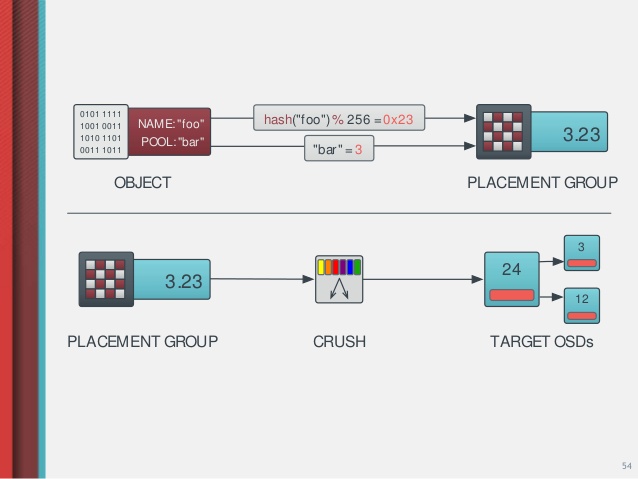
Ceph Clients and Ceph OSD Daemons both use the CRUSH algorithm to efficiently compute information about object location, instead of having to depend on a central lookup table. Ceph stores data as objects within logical storage pools. Using the CRUSH (Controlled Replication Under Scalable Hashing) algorithm, Ceph hashes the object to be stored, and dynamically calculates which placement group should contain the object. The CRUSH map is refered to further determine which Ceph OSD Daemon should store the placement group. The CRUSH algorithm enables the Ceph Storage cluster to scale, rebalance, and recover dynamically.
- Ceph Journal
Each Ceph OSD has a journal data associated with it, Ceph OSD Daemons write a description of the operation to the journal and apply the operation to the filesystem. Every few seconds the Ceph OSD Daemon stops writes and synchronizes the journal with the filesystem, allowing Ceph OSD Daemons to trim operations from the journal and reuse the space. On failure, Ceph OSD Daemons replay the journal starting after the last synchronization operation. In production environment, it is recomended to store journal data on SSD for better performance.
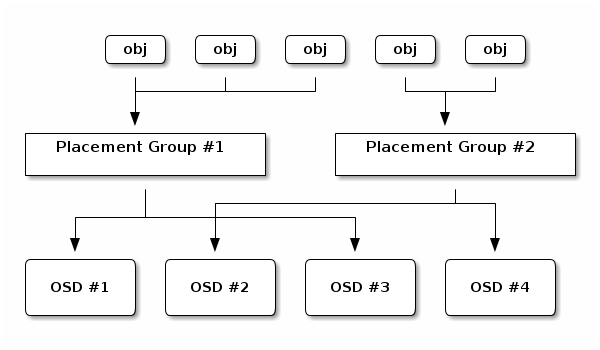
- Ceph Pool & Placement Group (PG)
A ceph pool is a logical partitions for storing objects. Each pool has a number of placement groups. CRUSH maps PGs to OSDs dynamically. The CRUSH algorithm maps each object to a placement group and then maps each placement group to one or more Ceph OSD Daemons. This layer of indirection allows Ceph to rebalance dynamically when new Ceph OSD Daemons and the underlying OSD devices come online. With a copy of the cluster map and the CRUSH algorithm, the client can compute exactly which OSD to use when reading or writing a particular object.
- Clock Sync
One of the critical aspect of ceph is the clock sync on the storage cluster. All the mon nodes need to be in time sync, as a scale-out system with synchronous replications, nodes needs to have the same exact time, otherwise bad things can happen. By default the maximum allowed drift between nodes is 0.05 seconds!! In our production cluster we had add this to our monitoring for determining the ceph clock skew and alerts were sent out.
- OSDs Service Clients Directly
Ceph Clients contact Ceph OSD Daemons directly, which increases both performance and total system capacity simultaneously, while removing a single point of failure. Ceph Clients can maintain a session when they need to, and with a particular Ceph OSD Daemon
- OSD Membership and Status
Ceph OSD Daemons join a cluster and report on their status. At the lowest level, the Ceph OSD Daemon status is up or down reflecting whether or not it is running and able to service Ceph Client requests. The OSDs periodically send messages to the Ceph Monitor, if the Ceph Monitor doesn’t see that message after a configurable period of time then it marks the OSD down. This mechanism is a failsafe, however. Normally, Ceph OSD Daemons will determine if a neighboring OSD is down and report it to the Ceph Monitor(s). This assures that Ceph Monitors are lightweight processes.
- Reblancing
Adding a new osd in the ceph cluster causes the cluster to rebalance. The cluster map gets updated with the new osd, consequently the object placement changes which changes the input for calculation. During rebalance process, some PG’s migrate to the new osd’s, but many of the PG’s stay in the same OSD. This might led to increase or decrease in disk space for an OSD.
When a Ceph OSD Daemon goes down, a placement group falls into a degraded state, etc.–the cluster map gets updated to reflect the current state of the cluster. Additionally, the Ceph Monitor also maintains a history of the prior states of the cluster.
- Replication
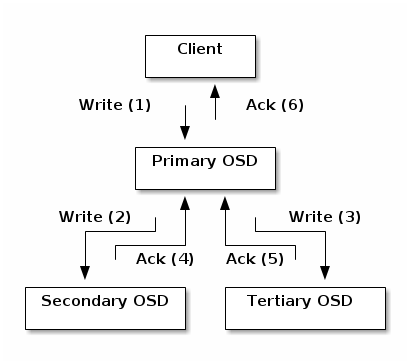
Like Ceph Clients, Ceph OSD Daemons use the CRUSH algorithm, but the Ceph OSD Daemon uses it to compute where replicas of objects should be stored (and for rebalancing). A client uses the CRUSH algorithm to compute where to store an object, maps the object to a pool and placement group, then looks at the CRUSH map to identify the primary OSD for the placement group. The client writes the object to the identified placement group in the primary OSD. Then, the primary OSD with its own copy of the CRUSH map identifies the secondary and tertiary OSDs for replication purposes, and replicates the object to the appropriate placement groups in the secondary and tertiary OSDs (as many OSDs as additional replicas), and responds to the client once it has confirmed the object was stored successfully.
- Scrubing
As part of maintaining data consistency and cleanliness, Ceph OSDs can also scrub objects within placement groups. That is, Ceph OSDs can compare object metadata in one placement group with its replicas in placement groups stored in other OSDs. Scrubbing (usually performed daily) catches OSD bugs or filesystem errors. OSDs can also perform deeper scrubbing by comparing data in objects bit-for-bit, Deep scrubbing is usually performed weekly.
- Ceph Authentication & Session
Ceph cluster uses a cephx authentication system to authenticate clients and daemons. Cephx uses shared secret keys for authentication, meaning both the client and the monitor cluster have a copy of the client’s secret key.
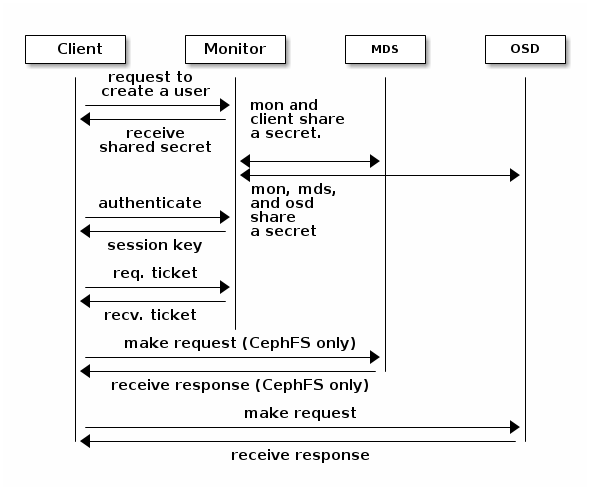
A user/actor invokes a Ceph client to contact a monitor.
The monitor returns an authentication ticket that contains a session key for use in obtaining Ceph services. This session key is itself encrypted with the user’s permanent secret key, so that only the user can request services from the Ceph Monitor(s).
The client then uses the session key to request its desired services from the monitor.
The monitor provides the client with a ticket that will authenticate the client to the OSDs that actually handle data.
Ceph Monitors and OSDs share a secret.
The client uses the ticket provided by the monitor with any OSD or metadata server in the cluster.
- Reference Links
Ceph Architecture Video explaination